消失的 Blob | 记一次问题排查
写在前面
前段时间处理了一个我觉得挺有意思的问题,于是有了想要记录下来一整个过程的冲动。趁着这股子劲儿还没散,得赶紧动笔写下来。因为我的草稿箱里已经囤积了不少想写的东西,但都是些零碎的文字片段,最终无限搁置成为了废稿(
回到正题,我的工作内容有一部分是处理用户反馈的工单(aka 客服)。要面对的反馈诸如:这个地方不翻译、那个功能怎么没生效、我想要你们实现 xxx…有些是用户的使用姿势不对(当然,这也可能跟我们的引导或文档不够完善有关),有些是 bug 或 Nice-to-have 的功能需求。
而今天我想聊的,是在适配某个漫画网站时遇到的一个 bug。
漫画翻译背后
某个下午,我正在处理漫画翻译相关的用户工单。一个用户反馈某个漫画网站无法翻译。于是我便点进该网站,着手相应的适配工作。在进入正题前,我想先简单聊聊浏览器扩展的漫画翻译是如何工作的。
从前端角度看,实现漫画翻译的逻辑并不复杂(这里特指服务端翻译,如果放在端侧去做的话会麻烦一些)。本质上我们要做的是:
- 获取原图:拿到网页中渲染的漫画图片(根据网站实现不同,可能是
<img>、background-image或<canvas>) - 图像处理:进行一系列处理流程:
OCR(识别) →Inpainting(擦除) →Translate(翻译) →Layout(排版) →Rendering(渲染) - 回填替换:用处理好的新图片替换掉网站原图
但正如我在上面提到的,仅考虑漫画翻译这个场景,不同网站之间就有不少差异。图片渲染方式的不同只是其中之一。面对着茫茫多的网站,怎么抽象出一套合理的方案来兼容各种奇奇怪怪的 case 也就成了无法绕过的一环。而我们采用的是配置驱动的方案:在浏览器扩展中内置一套基础配置,并针对特定网站编写专属配置,这些配置相互独立。如此既可以对某些热门网站进行深度的适配和优化,又能兼容不同网站间的差异。若用户有一定的前端基础,还可自行定制来完善翻译体验。并且这份配置是通过云端下发给扩展,使我们能够在改坏配置有需要的时候快速调整,无需发版。
排查过程
好了,至此需要提供的上下文已经完整。接下来讲讲我一般是怎么适配漫画网站的。我一般会先观察网页的 HTML 结构:
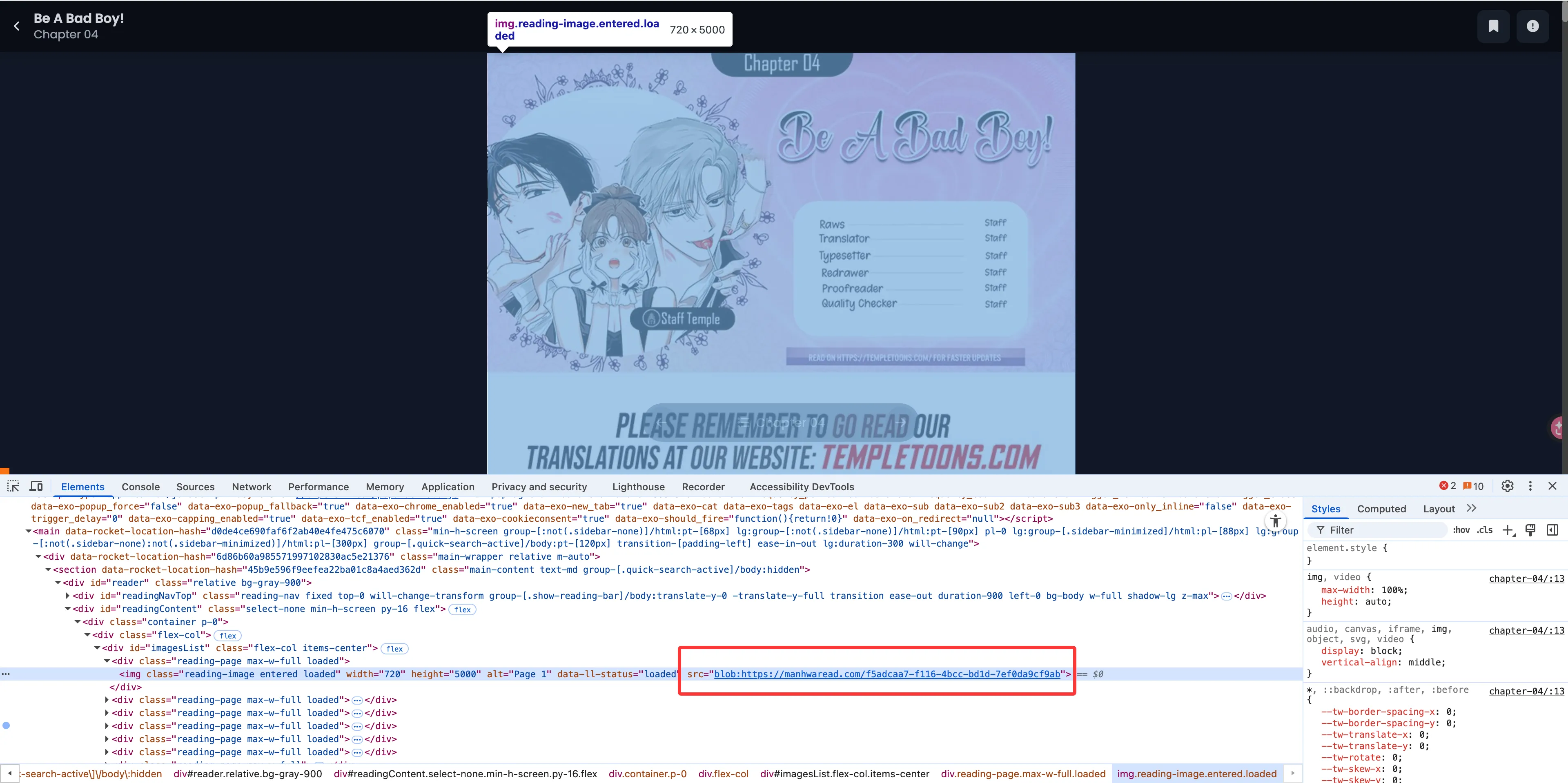
如上图所示,可以看到图片有一个特点:src 的前缀是 blob:。这说明网站通过 URL.createObjectURL 来展示图片,也意味着用户无法通过右键菜单另存/复制来获取原图。这么做主要是为了防盗链和反爬,算是一种保护内容的手段。不过浏览器扩展的 content script 与宿主页面共享同一上下文,因此这个限制对扩展来说形同虚设,直接 fetch(blobUrl) 即可…吗?
果然,不出意外还是出意外了。触发翻译时,得到了如下报错:
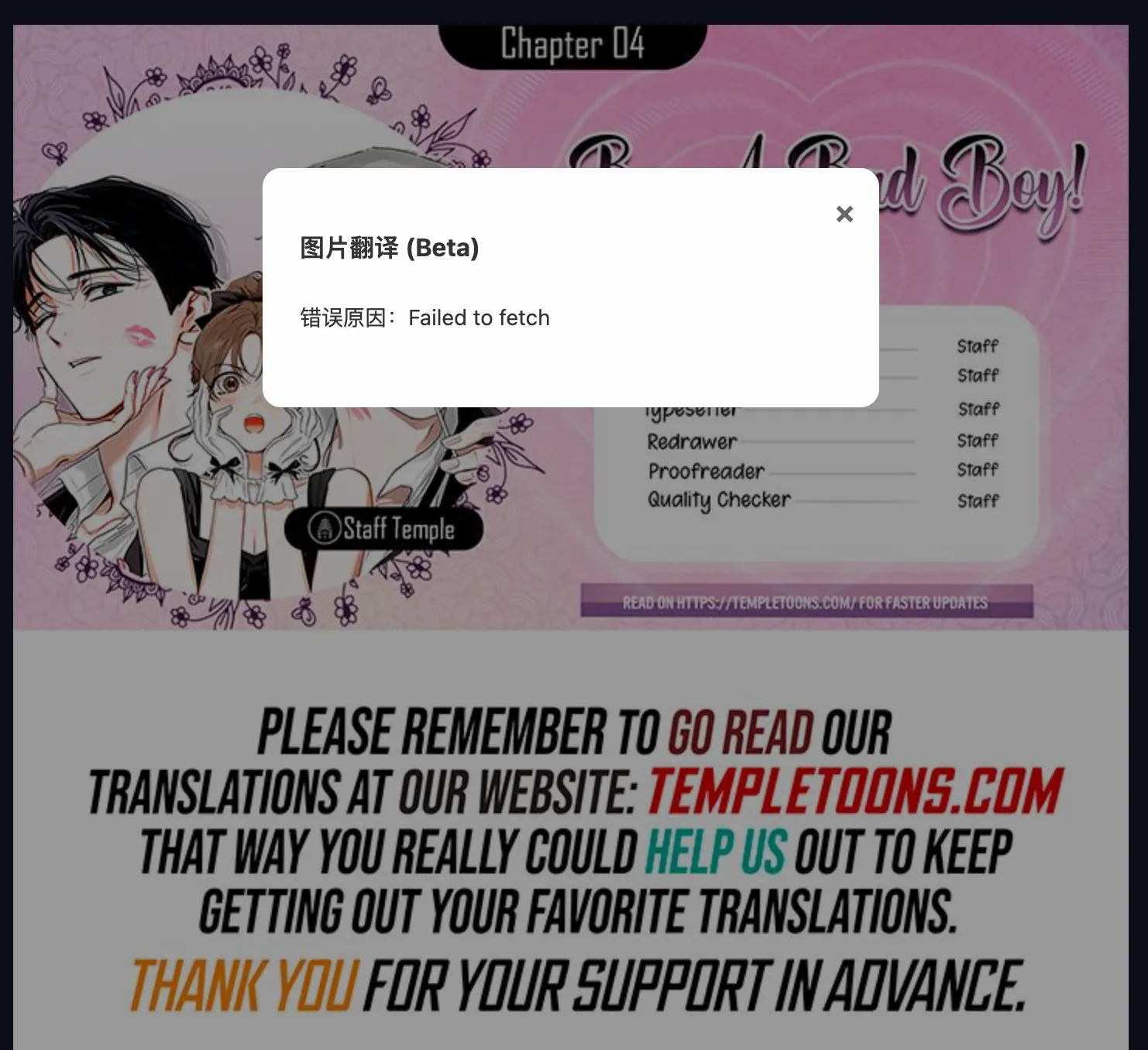
嗯…fetch 失败了,会是什么原因呢?初步怀疑可能是 blob 资源被提前释放了。在 Web API 中,URL.createObjectURL() 创建的 URL 是临时的,一旦执行了 URL.revokeObjectURL(),该 URL 就会失效,对应的内存资源也会被释放。
但是如何验证猜想呢?大胆假设,小心求证。既然网站很大概率对图片资源进行了清理,那么就说明该网站的脚本中必然会存在执行相关逻辑的代码。这意味着只要我们能够利用 Debugger 断点到执行该操作的时刻,便能够一探究竟。现在,让我们进入分析。
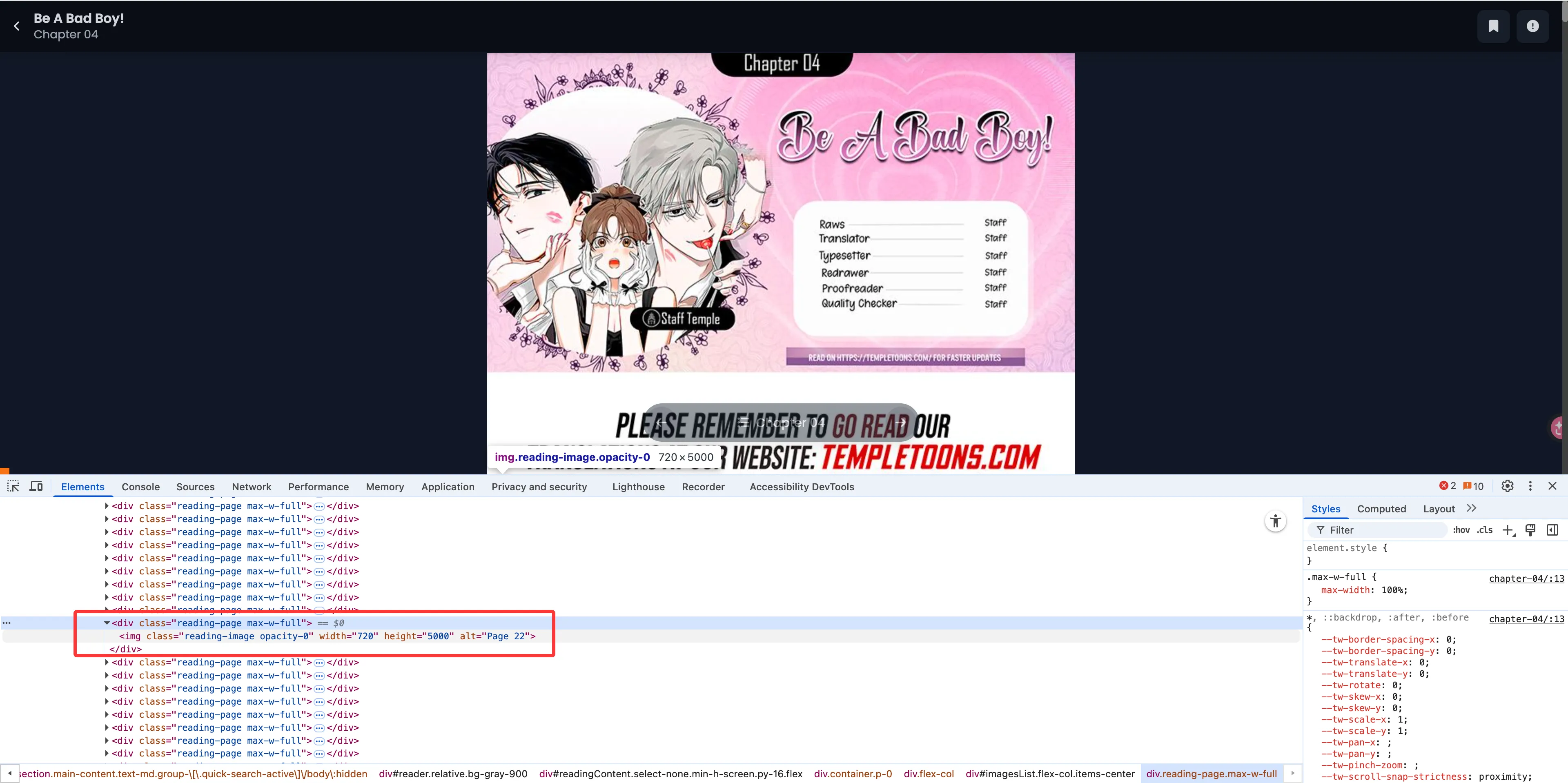
上图中我们可以看到,该网站的图片是做了懒加载的。视口外的 img 元素并没有 src 属性。那么就很简单了,我们可以通过 Devtool 对该图片加上 DOM 断点,触发后看 call stack。
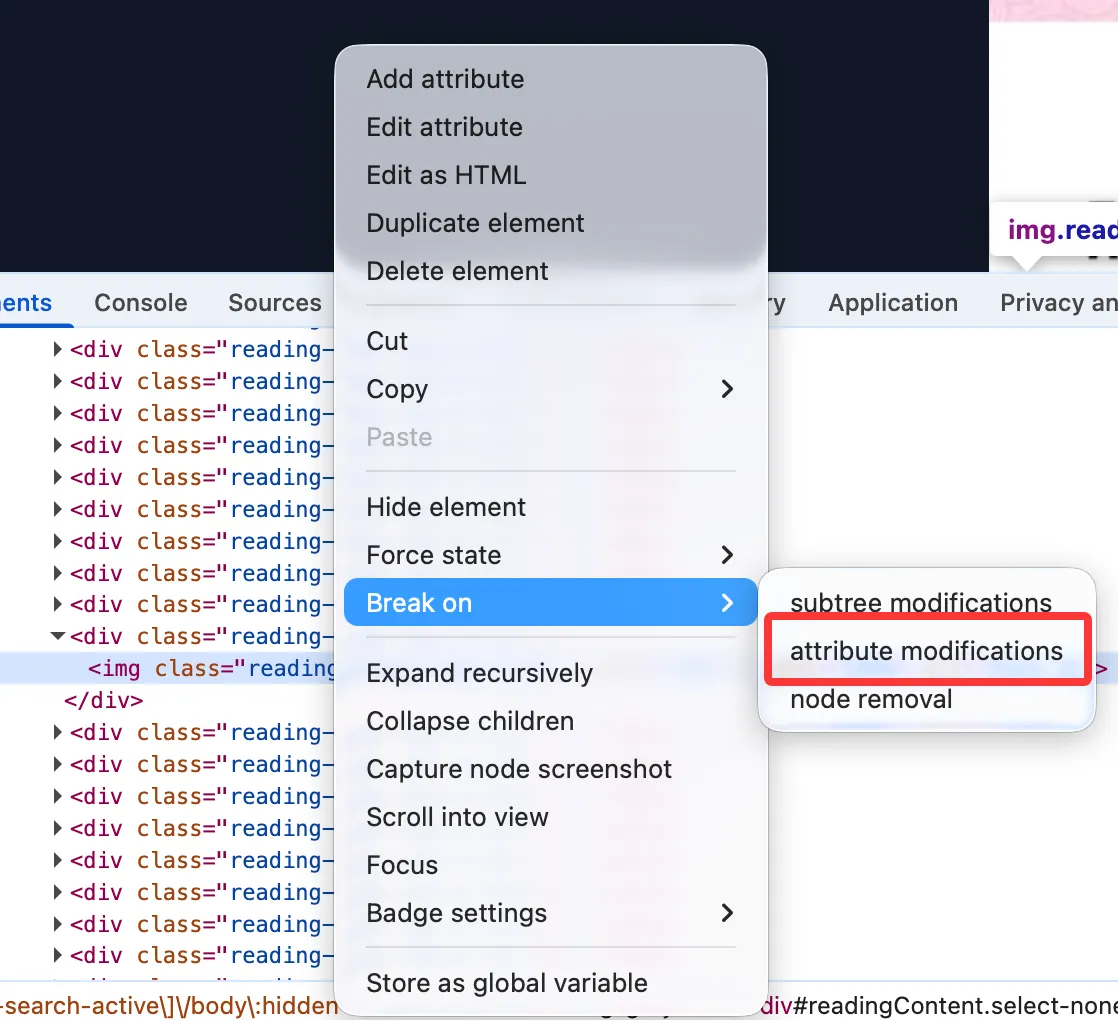
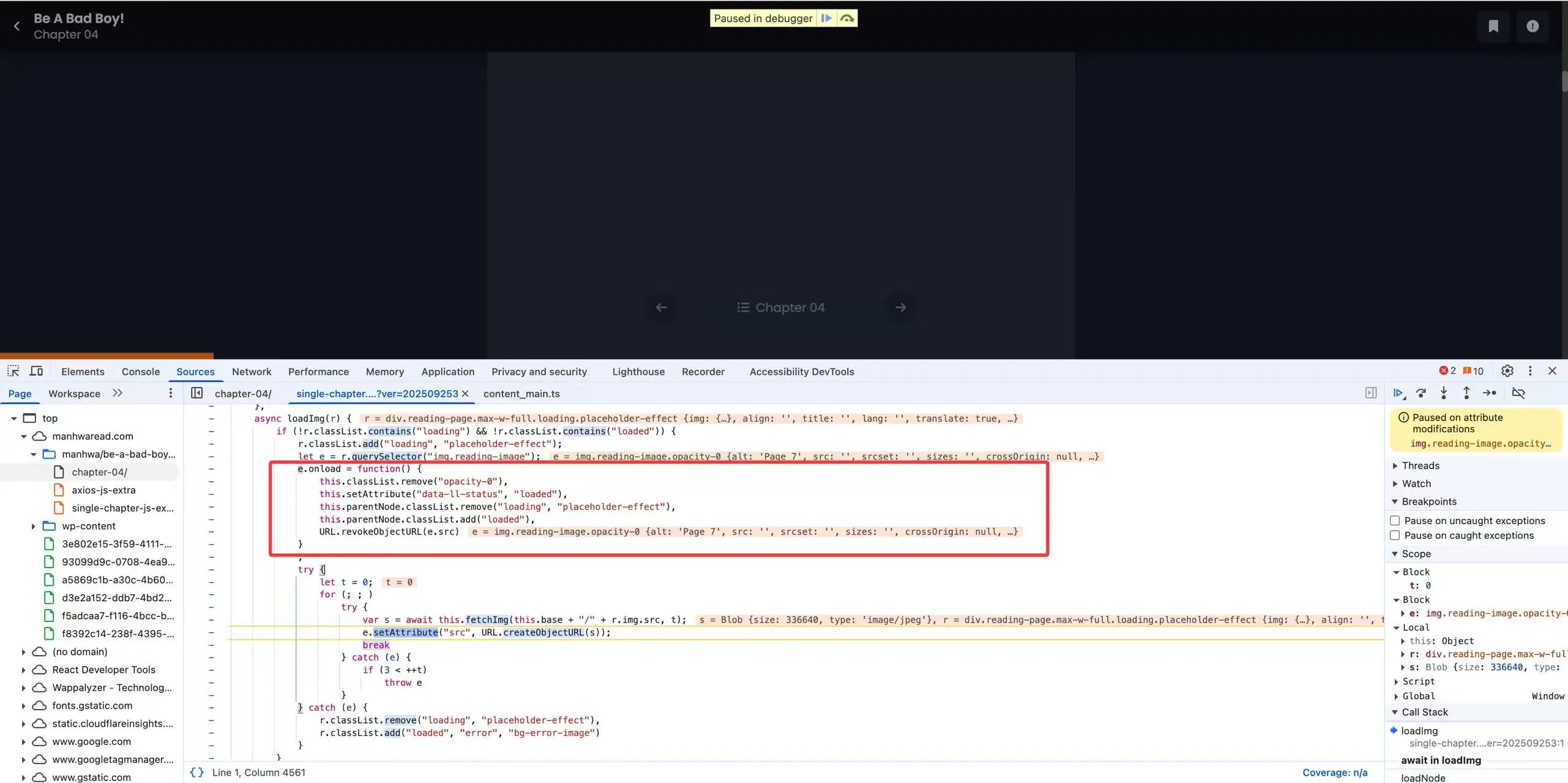
很好,答案已经出现:在网站的 JavaScript 脚本中,loadImg 函数是图片加载的逻辑。它通过调用 URL.createObjectURL来创建 blob 对象,并且在图片的 onload 事件中(即图片加载完成时),通过 URL.revokeObjectURL 释放资源。于是导致了我们漫画翻译在获取图片这一步失败了。
那么,我们现在已经明确了造成图片翻译失败的根因,下一步就该着手解决了(其实似乎略过这一步也行,但请原谅我的好奇心)。
既然图片的 blob 已经被释放,那该怎么获取原图呢?可以明确的一点是:图片本身已经被浏览器解码,渲染在 DOM 中了。所以理论上我们能够通过某种手段来获取到它的像素。于是乎,canvas 登场了。在 canvas 中有一个 drawImage 方法,它提供了多种将图像绘制到画布上的方式。那我们只需要 drawImage(img) 到离屏 canvas,再通过 canvas.toBlob(),把数据喂给后端翻译接口即可。核心代码大概是这样:
function getBlobByImageElement(imgEle: HTMLImageElement): Promise<Blob | null> {
return new Promise((resolve, reject) => {
try {
const canvas = document.createElement('canvas')
canvas.width = imgEle.naturalWidth
canvas.height = imgEle.naturalHeight
const ctx = canvas.getContext('2d')
if (!ctx) {
reject('can not get canvas context')
return
}
ctx.drawImage(imgEle, 0, 0)
canvas.toBlob((blob) => resolve(blob), 'image/png')
} catch (error) {
reject(error)
}
})
}最后让我们验证一下效果,everything works well~
总结
这便是我工作日常中的一个小小片段,在各种各样的坑里摸爬滚打,顺带着收获了不少知识、技巧。希望我的排查思路和过程能够对你起到一点帮助。
一点题外话
人类的思想就是没有经过整理的无数杂念的混合。—— 《黑客与画家》
时隔近两年,我终于再次提笔写下了一篇文章。整个过程还是挺坎坷的:从整理想法到完整表述,再到最后调整行文结构、优化措辞表述,花了几天的时间。 我重新捡起写作很大程度上是因为 AI:它正试图全面介入我们的生活,代替我们执行,甚至想替我们思考、决策。在这种大环境下,我该如何保持独立思考,培养自己的品味和判断力呢?写作是我认为的最佳手段。它迫使着我深入思考,这个过程也会催生出新的想法。
最后,感谢阅读。对我来说这是一个新的开始,后续我的写作方向可能主要还是技术相关的。日常碎碎念的话在这里。
如果此文也能够唤起你写作的念头,那么真是我莫大的荣幸了。